

Czym jest Sztuczna Inteligencja? W przestrzeni prawnej funkcjonuje kilka definicji Sztucznej Inteligencji, w skrócie SI (ang. Artificial Intelligence, AI). Według jednej z nich jest to „dziedzina wiedzy obejmującą m. in. sieci neuronowe, robotykę i tworzenie modeli zachowań inteligentnych oraz programów komputerowych symulujących te zachowania, włączając w to również uczenie maszynowe (ang. machine learning), głębokie uczenie (ang. deep learning) oraz uczenie wzmocnione (ang. reinforcement learning).”[1]
Nieco bardziej szczegółowo i wieloaspektowo zdefiniowała Sztuczną Inteligencję Komisja Europejska pisząc w dokumentach dotyczących wdrożenia regulacji w obszarze Sztucznej Inteligencji, że są to: „(…) zaprojektowane przez ludzi systemy oprogramowania (i ewentualnie również sprzętu), które, biorąc pod uwagę złożony cel, działają w wymiarze fizycznym lub cyfrowym, postrzegając swoje środowisko poprzez pozyskiwanie danych, interpretując zebrane ustrukturyzowane lub nieustrukturyzowane dane, rozumując na podstawie wiedzy lub przetwarzając informacje, uzyskane z tych danych i decydując o najlepszym działaniu (działaniach), jakie należy podjąć, aby osiągnąć dany cel. (…) AI obejmuje kilka podejść i technik, takich jak uczenie maszynowe (którego konkretnymi przykładami są uczenie głębokie i uczenie wzmacniające), rozumowanie maszynowe (które obejmuje planowanie, harmonogramowanie, reprezentację wiedzy i rozumowanie, wyszukiwanie i optymalizację) oraz robotykę (która obejmuje sterowanie, percepcję, czujniki i siłowniki, a także integrację wszystkich innych technik w systemy cyber-fizyczne).”[2] Zdefiniowanie zjawiska Sztucznej Inteligencji funkcjonującej w przestrzeni publicznej oraz prywatnej stało się konieczne, kiedy zorientowano się, że zaczęła się ona wymykać z ram obowiązującego prawa stwarzając zagrożenie związane z niedookreśloną odpowiedzialnością za jej działania, zaniechania oraz wykorzystywanie informacji w formie baz danych z informacjami poufnymi. W tym informacji wrażliwych lub poufnych. Zagrożenia stosowania SI wynikają z otoczenia zewnętrznego i są związane z cyberatakami na bazy danych lub ingerencją w algorytmy. Jednak o wiele poważniejszym zagadnieniem jest zagrożenie wewnętrzne, związane z konsekwencjami decyzji podjętych przez Sztuczną Inteligencję w toku uczenia maszynowego, na podstawie jej własnej interpretacji danych w kontekście poleceń sformułowanych w danym modelu. Dlatego Unia Europejska w ramach współpracy wszystkich państw członkowskich podjęła się zdefiniowania i identyfikacji ryzyk wynikających z powszechnego stosowania rozwiązań SI w różnych sferach życia i sektorach gospodarki w celu ich ograniczenia, ale z jednoczesnym zachowaniem dynamicznego rozwoju Sztucznej Inteligencji we wszystkich aspektach życia społecznego i gospodarczego opierając się na założeniu: „doskonałości i zaufaniu, mając na celu zwiększenie potencjału badawczego i przemysłowego przy jednoczesnym zapewnieniu bezpieczeństwa i praw podstawowych.”[3]
W Polsce temat rozwoju SI w sposób systemowy podjęto całkiem niedawno bo w trzecim kwartale 2023 r. Doszło do zainicjowania działań zmierzających do powołania Polskiego Komitetu Normalizacyjnego w Sektorze Technik Informacyjnych i Komunikacji Komitetu Technicznego ds. Sztucznej Inteligencji. Tematyka prac Komitetu ma w założeniach obejmować: aspekty normalizacji związane z obszarem Sztucznej Inteligencji, w tym rozwiązania prawne i techniczne zapewniające rozwój godnych zaufania systemów Sztucznej Inteligencji, szanujących podstawowe wartości i prawa człowieka. Niezbędne w tym celu jest opracowywanie, a następnie przyjmowanie norm dotyczących SI i związanych z nią danych w procesie legislacji. Według założeń Komitet ds. Sztucznej Inteligencji będzie Komitetem wiodącym w zakresie współpracy europejskiej z CEN/CLC/JTC 21 Artificial Intelligence oraz międzynarodowej ISO/IEC JTC 1/SC 42 Artificial Intelligence.
Sztuczna Inteligencja kojarzona jest z wizją komputera lub humanoidalnego robota. Często jest wizualizowana jako robot o ludzkich cechach. Oczekujemy, że będziemy się z nią komunikować i wchodzić w interakcje bez ograniczeń. W założeniach wynikających z potrzeb ludzkich ma być ona naszym doradcą, asystentem codziennego życia, współpracownikiem, rozwiązującym samodzielnie lub wspólnie problemy. W założeniach potrzeb przemysłu ma ona zastępować ludzi oraz realizować procesy, które bez udziału maszyn nie byłyby możliwe do przeprowadzenia w akceptowalnym obecnie czasie. W interakcjach z maszynami, urządzeniami i sprzętem codziennego użytku oraz technologiami wykorzystywanymi w przemyśle zbierane są systematycznie obserwacje i jako zmienne służą do tworzenia profilu użytkownika, czy procesu technologicznego. „Czujniki pomiarowe” Sztucznej Inteligencji monitorują zarówno przestrzeń prywatną, jak i publiczną funkcjonującą w warstwie technologicznej. Mogą stworzyć profil potrzeb użytkownika na przykład w zakresie komfortu cieplnego lub dostaw energii elektrycznej na przestrzeni doby, miesiąca, czy roku. Udoskonalenie usługi polegającej na zapewnieniu komfortu cieplnego, korzystania z ciepłej wody, czy urządzeń elektrycznych wymaga interakcji z odbiorcą i danych o profilu jego potrzeb. Tylko wówczas Sztuczna Inteligencja będzie w stanie zrealizować wizję inteligentnego domu, mieszkania i umożliwi wejście na nowy poziom poprawy warunków życia. Bez bazy danych z przeszłości SI nie może zaistnieć, a by funkcjonowała musi tą bazę cały czas uzupełniać. Aby stworzyć SI, która potrafi wykorzystać potencjał danych – niezbędna jest wiedza o narzędziach pozwalających na wnioskowanie i uczenie się z tych danych. Wiedza o rodzajach i możliwościach modeli algorytmów. SI funkcjonuje dzięki algorytmom programującym działania maszyn. SI działa w maszynach, które mają zdolność uczenia się na podstawie baz danych, które im udostępniono. Algorytm może mieć formę hipotezy, pytania lub polecenia. Główne kategorie tworzonych algorytmów to algorytm genetyczny oraz algorytm sieci neuronowej. Algorytm genetyczny poszukuje odpowiedzi analizując bazy danych oraz wskazując alternatywne rozwiązania sformułowanego problemu w celu wyszukania najlepszych rozwiązań. Działanie algorytmu genetycznego jest realizowane w następujących krokach:
- ustalenie reprezentatywnego wyniku,
- ustalenie funkcji przystosowania/dopasowania,
- ustalenie operatorów przeszukiwania.
Na potrzeby algorytmu można zastosować różne metody selekcji do powyższych ustaleń. Jedną z nich jest metoda rankingowa, która poprzez funkcję oceny reprezentatywnych wyników i porządkuje je od najlepszego do najgorszego. Przykładem takiego modelu dla zastosowania w algorytmie może być metoda Hellwiga doboru takiej kombinacji zmiennych do modelu, która zawiera największą integralną pojemność informacji o szukanym wyniku. Inną metodą pozwalającą osiągnąć dobre wyniki selekcji „genetycznej” może być analiza wielokryterialna, która pozwala na stworzenie rankingu. Jedną z jej bardziej złożonych wersji jest metoda unitaryzacji zerowej, w skrócie MUZ. Algorytmy genetyczne posiadają mechanizm umożliwiający analizę wielu alternatywnych rozwiązań oraz umożliwiają grupowanie danych i wyników.
Algorytm sieci neuronowej ma inne zadanie. Jest on bowiem przeznaczony do przetwarzania informacji. Jego budowa i zasada działania są wzorowane na funkcjonowaniu systemu nerwowego i komunikacji pomiędzy synapsami – w celu podjęcia decyzji lub podjęcia działania. Wyróżniającą cechą sieci neuronowej, jako algorytmu opartego o metody analityczne, jest możliwość rozwiązywania problemów bez ich uprzedniej matematycznej formalizacji. Mają w tym przypadku zastosowanie narzędzia informatyczne reprezentujące uczenie się i rozumowanie maszynowe. Inną istotną cechą tego rodzaju algorytmów jest brak konieczności odwoływania się, przy stosowaniu sieci neuronowej, do jakichkolwiek teoretycznych założeń na temat rozwiązywanego problemu. Sieci neuronowe posiadają zdolność uczenia się na podstawie analogii lub przykładów oraz uogólniania zdobytej wiedzy w procesie generalizacji. Sztuczne sieci neuronowe mają zastosowanie w:
- aproksymacji,
- prognozowaniu,
- przewidywaniu danych wyjściowych na podstawie danych wejściowych bez konieczności jawnego definiowania zależności pomiędzy nimi;
- klasyfikacji i rozpoznawania;
- kojarzenia danych – sieci neuronowe pozwalają zautomatyzować procesy wnioskowania i pomagają wykrywać istotne powiązania pomiędzy danymi;
- analizy danych, czyli poszukiwania związków pomiędzy danymi.
Szeroko stosowane są sieci rekurencyjne opierające się na analizie zależności pomiędzy zmiennymi dostępnymi w bazie danych w celu wyszukania optymalnego rozwiązania. Przykładem zastosowania sieci neuronowych do rozwiązania praktycznych problemów logistycznych, istotnych w energetyce, jest tzw. problem komiwojażera.
Sektor energetyczny jest jednym z powszechnie już obecnie wykorzystujących Sztuczną Inteligencję w procesach sterowania systemami na poziomie logistyki, wytwarzania, przesyłu oraz dystrybucji – implementując techniki uczenia maszynowego oraz robotyki. Dlatego istotnym zagadnieniem staje się zdefiniowanie potencjału rozwoju SI z jednej strony oraz ryzyk z tym związanych z drugiej. Energetyka, w tym ciepłownictwo, jako usługa powszechna jest obecnie niezbędnym elementem zapewnienia bezpieczeństwa publicznego i bezpieczeństwa państwa. Sektor energetyczny został zaliczony do ośmiu obszarów, w których wykorzystanie SI może negatywnie wpływać na bezpieczeństwo lub prawa podstawowe, co klasyfikuje go do kategorii systemów wysokiego ryzyka. Aktualnie w UE opracowywane są już ramy prawne stosowania rozwiązań Sztucznej Inteligencji w sektorze energetycznym stanowiącym infrastrukturę krytyczną, gwarantującą bezpieczeństwo zarówno na poziome krajowym, jak i unijnym. Zgodnie z Aktem w sprawie Sztucznej Inteligencji przypadki zastosowania Sztucznej Inteligencji w sektorze energetycznym będą musiały zostać zarejestrowane w unijnej bazie danych. Aby zidentyfikować taki „przypadek” ponownie należy wrócić do definicji co Sztuczną Inteligencją w energetyce jest, a co nią nie jest teraz i w przewidywalnej przyszłości. Przeanalizujmy w tym aspekcie oraz w aspekcie zastosowania SI sektor ciepłowniczy, jako jeden z elementów systemu energetycznego.
Systemy ciepłownicze już obecnie dysponują dużymi zasobami danych, które poddane analizie mogą być wykorzystane do optymalizacji technologicznej oraz ekonomicznej procesów w przedsiębiorstwach. Problemy technologiczne w coraz bardziej złożonych systemach zdecentralizowanych źródeł dotyczą planowania konfiguracji pracy poszczególnych źródeł oraz zbilansowania potrzeb sieci ciepłowniczej z dostępnymi mocami źródeł w danej chwili. Doskonałe narzędzia do rozwiązywania tego typu problemów oferuje dział metod statystycznych zwany badaniami operacyjnymi. Najbardziej przydatne w ciepłownictwie mogą być modele programowania liniowego lub nieliniowego oraz programowanie sieciowe. W dużych grupach kapitałowych, w których funkcjonują tzw. centra usług analizujące bieżące dane oraz tworzące prognozy dla polityki zakupu paliw, energii lub usług wykorzystujące metody optymalizacji zagadnień transportowych. Dzieląc się danymi ich dotyczącymi z odbiorcami na poziomie zarządzających obiektem lub budynkiem przedsiębiorstwa z branży ciepłowniczej tworzą świadomych użytkowników systemu i umożliwiają im podjęcie działań proefektywnościowych. Aktualnie gromadzone i archiwizowane bazy danych o parametrach nośnika, temperaturze otoczenia, ciśnieniu, czy przepływie – w większości nie mają charakteru danych wrażliwych, gdyż nie dotyczą osób fizycznych. Przetwarzanie tego typu danych nie jest objęte ochroną. Bardziej spersonalizowane dane, dotyczące konkretnych gospodarstw domowych gromadzone są przez dostawców energii elektrycznej, czy gazu. W ciepłownictwie zdarzają się odbiorcy indywidualni reprezentujący gospodarstwo domowe mieszkające w domu jednorodzinnym, jest to jednak nikły odsetek całej populacji odbiorców. Jednak i w tym przypadku nie ma zobowiązań do ochrony takich danych. Cyberatak polegający na kradzieży tego typu danych nie stanowi aktualnie dla przedsiębiorstw problemu w zakresie odpowiedzialności, jak za dane personalne. Jednak cyberatak wykonany przez SI, który poprzez atak na bazę danych powodowałby dysfunkcję systemu ciepłowniczego może powodować zagrożenie dla uszkodzenia mienia, zdrowia lub bezpieczeństwa dostaw o dużej skali i wartości strat. Taki przypadek zagrożenia stanowi więc istotne ryzyko na poziomie efektu zastosowania SI przez czynniki zewnętrze w postaci problemu prawnego w zakresie dochodzenia szkód i egzekwowania odpowiedzialności. Podobnie jak utrata baz danych umożliwiających sterowanie systemem ciepłowniczym na skutek samoistnych decyzji SI stanowiącej nadrzędny system sterowania na skutek jej wewnętrznej usterki, błędu algorytmu. Taki przypadek rodziłby podobne implikacje, jak wyżej opisany. Rozważanie na temat tego typu ryzyk jest o tyle ważne, że zarówno algorytmy genetyczne, jak i sieci neuronowe – będą miały coraz szersze zastosowanie w ciepłownictwie, które w obszarze ciepła ma charakter lokalny, ale jako kogeneracja jest elementem systemu elektroenergetycznego. Aby zidentyfikować ryzyka, ocenić prawdopodobieństwo ich wystąpienia oraz skalę zagrożenia trzeba mieć świadomość obszarów zastosowania SI.
Algorytm genetyczny w energetyce w może mieć zastosowanie jako nadrzędny system sterowania profilem pracy źródeł wytwarzania oraz parametrami ich pracy w celu optymalizacji współpracy z siecią ciepłowniczą, energetyczną oraz optymalizacji ekonomicznej. Bazę dla tworzenia algorytmu sieci neuronowej w celu optymalizacji profilu pracy źródeł mogą stanowić metody programowania liniowego PL, w tym metody Simplex, w których funkcję celu można zapisać w postaci macierzowej, jak niżej:
f(x) = cT x → max lub min
Warunki ograniczające model programowania liniowego w postaci macierzowej zapisujemy następująco:
Ax ≤ b
x ≥ 0
gdzie:
x – wektor zmiennych, udział mocy źródeł w systemie ciepłowniczym,
c – wektor współczynników funkcji celu (wag) cen zakupu ciepła ze źródeł lub kosztów wytwarzania w systemie własnym,
A – macierz współczynników (kombinacji równoważnej), moce źródeł w systemie ciepłowniczym,
b – wektor wyrazów wolnych (prawa strona – RHS), ograniczenia techniczne lub ekonomiczne.
Natomiast funkcję celu w postaci kanonicznej, równania lub nierówności uwzględniając konkretny układ zmiennych oraz współczynników zapisujemy następująco:
f(x) = c₁₁x₁₁ + c₁₂x₁₂ + (…) + c₁ₙx₁ₙ + c₂₁x₂₁ + c₂₂x₂₂ + (…) + c₂ₙx₂ₙ ⇒ max lub min
Układ równań lub nierówności dla warunków ograniczających w postaci kanonicznej zapisujemy jak niżej:
a₁₁x₁₁ + a₁₂x₁₂ + (…) + a₁ₙx₁ₙ ≤ b₁ₙ
……………………………………….
aₘ₁xₘ₁ + aₘ₂xₘ₂ + (…) + aₘₙxₘₙ ≤ bₘₙ
x₁₁, x₁₂, (…), xₘₙ ≥ 0
Modelowanie liniowe wymaga dość skomplikowanych działań na macierzach w celu rozwiązania metodami klasycznymi. Dlatego doskonale sprawdza się tu SI. Prawidłowe sformułowanie problemu do rozwiązania pozwoli na obliczenie optymalnego profilu pracy źródeł lub parametrów pracy sieci, w tym lokalnie kilka sekund, algorytm dynamiczny pobierałby dane z bieżącymi cenami informacyjnymi na CRO lub notowaniami RDN w zestawieniu z prognozą danych technologicznych sieci, tj. przepływ, temperatury, czy ciśnienie. Jednak musi to poprzedzać dokładna analiza ograniczeń związanych z bilansowaniem zasobów i precyzyjne wyliczenie kosztów i przychodów jednostkowych z poszczególnych źródeł. Taki model optymalnej pracy systemu ciepłowniczego w aspekcie ekonomicznym można stworzyć także w oparciu o definicję modelu progu rentowności. Przykłady algorytmów, które mogą być wykorzystywane przez SI nadające im wymiar dynamiczny, samouczący zawiera tabela 1.
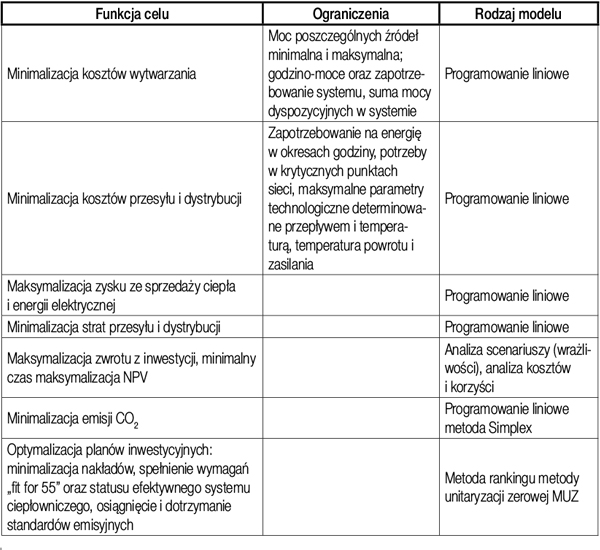
Sterowanie parametrami można realizować z wykorzystaniem algorytmu genetycznego modeli ekonometrycznych. Przykładem praktycznego zastosowania SI na poziomie algorytmu genetycznego jest system sterowania systemem ciepłowniczym w Elektrociepłowni Ciechanów, gdzie wdrożono i cały czas udoskonala się inteligentny systemu nadzoru i sterowania siecią ciepłowniczą, w skrócie ISNiSC. Pozwala on wspierać procesy związane z bieżącą eksploatacją sieci ciepłowniczej w wymiarze dynamicznym. ISNiSC umożliwia uzyskanie optymalnych parametrów pracy z uwzględnieniem pracy źródeł ciepła i komór cieplnych oraz sieciowych i odbiorczych elementów regulacyjnych i pomiarowych. System oferuje następujące funkcjonalności:
- efektywną komunikację z rozproszonymi obiektami sieci ciepłowniczej,
- funkcje zdalnego sterowania i monitorowania przebiegu procesów technologicznych,
- sterowania siecią ciepłowniczą zgodnie z wybranymi wskaźnikami jakości,
- sterowanie profilem pracy źródeł ciepła i energii elektrycznej,
- generowanie raportów pozwalających ocenić efektywność procesów,
- wsparcie dla budowy modeli wykorzystywanych w analizach dotyczących rozwoju i predykcji zachowania się sieci ciepłowniczej, w tym identyfikację ryzyka wystąpienia awarii.
Ze względu na dużą złożoność, system nadzoru wymaga odpowiedniej dystrybucji zadań do rozproszonych inteligentnych podsystemów typu smart współpracujących ze sobą. System działa wielowarstwowo. Komponenty tworzące system wzajemnie się komunikują na wspólnej platformie. W tym celu zostały wyposażone w odpowiednie kompatybilne z systemem interfejsy komunikacyjne. Jednym z pytań skierowanych do SI do budowanego systemu brzmiało: Które z rozwiązań pozwoli na skuteczną realizację dostaw w obliczu awarii sieci magistralnej? Analiza w ramach pracy SI analizujących parametry pracy sieci pozwoliła na wytypowanie punktów krytycznych jeżeli chodzi o utrzymanie ciśnienia w węzłach odbiorczych oraz tzw. „punktu ciężkości” sieci. „Punkt ciężkości” należy rozumieć jako miejsce, w którym najbardziej uzasadniona jest lokalizacja awaryjnego źródła alternatywnego dla centralnej ciepłowni oraz punkt, który dzieli dwa główne obszary zasilania miasta. Sugestie zostały wykorzystane w strategii rozwoju. Inne pytanie dotyczyło nastawy ciśnienia dyspozycyjnego w systemie. Odpowiedź dała analiza dynamiczna bieżących pomiarów parametrów sieciowych na wszystkich końcówkach sieci cieplnej, co pozwoliło na optymalizację parametrów temperatury zasilania sieci i dostosowaniu przepływu oraz tym samym oszczędność na pompowaniu. Ponieważ pomiary są dostępne w interwałach 15 min, można przeprowadzić pogłębioną analizę każdego licznika ciepła zamontowanego w węźle i na bieżąco prowadzić analizę schłodzenia ∆T i wskaźnika ilości przetłoczonego czynnika m3 na ilość sprzedanej energii GJ. Dzięki temu możliwa jest identyfikacja i stworzenie rankingu priorytetowych działań technicznych, takich jak np.: dokryzowanie, wymiana pomp, czyszczenie wymienników. Zagadnienie sterowania siecią ciepłowniczą współpracującą z system elektroenergetycznym jest dość skomplikowane z uwagi na akumulacyjność sieci, opóźnienia wzajemnych zależności oraz zmienność warunków pogodowych (coraz większa na skutek ocieplania klimatu). Dynamiczny model sieci i blok programistyczny stanowi wsparcie do prognozowania w trybie nadążnym zapotrzebowania mocy sieci i pożądanych parametrów wysyłanych do sieci. System pozwala na wskazanie punktów odcięcia w celu ograniczenia skutków ewentualnej awarii, dzięki zastosowaniu zdalnie sterowanych przepustnic (wizualizacja ciągłego monitoringu w punktach krytycznych, punktach odniesienia, komorach wyposażonych w pomiar parametrów czynnika oraz zdalnie sterowane przepustnice oraz parametry pracy źródła, pogodowe warunki zewnętrzne i wykresy istotnych parametrów pracy sieci i źródła). Monitoring sprawdza się idealnie w czasie awarii i przywracaniu dostaw, ponieważ pozwala na prześledzenie historii pracy sieci w rzeczywistych warunkach ekstremalnych oraz wskazanie obszarów i odcinków krytycznych z uwagi na czas przywracania dostaw ciepła. Wizualizacja pracy w punktach odbioru oraz pracy sieci w stanie rzeczywistym jest narzędziem pozwalającym dyspozytorowi sieci na utrzymanie pełnej kontroli nad odcinaniem i przywracaniem dostaw na poszczególnych odcinkach oraz identyfikacji miejsca awarii. System monitoringu uzupełniono o wizualizację pomiaru w czasie rzeczywistym stanu rezestancji sieci preizolowanej. System monitoringu pozwala na wytypowanie odcinków wysokiego i potencjalnego ryzyka wystąpienia awarii. To są pozytywne efekty zastosowania rozwiązań spełniających definicję i mających charakter SI. W przypadku Elektrociepłowni Ciechanów Sp. z o.o. SI służy jako narzędzie analityczne i rekomendujące działania, a decyzje pozostawiono operatorowi. Brane są bowiem pod uwagę opisane wyżej ryzyka zastosowania rozwiązań, związane z wewnętrzną dysfunkcją SI lub ryzyka jej wykorzystania w cyberataku. Mogły by to być poważne zagrożenia co do skali negatywnych efektów na poziomie miasta oraz całej sieci elektroenergetycznej. Trzeba mieć to na uwadze w dobie aktualnych niepokojów geopolitycznych.
Sieci neuronowe mają również już obecnie zastosowanie do prognozowania parametrów pracy sieci ciepłowniczej w odpowiedzi na zapotrzebowanie odbiorców oraz parametry pogodowe. Są stosowane do diagnostyki pracy sieci ciepłowniczej, w tym wykrywania potencjalnych uszkodzeń sieci lub innych awarii. Odchyłki lub anomalie w stosunku do prognozowanych wartości ciśnienia, przepływu i temperatury pozwalają przewidzieć lub zidentyfikować awarię sieci ciepłowniczej na podstawie analizy danych ex post z monitoringu pracy tej sieci. Wczesne rozpoznanie umożliwia podjęcie szybkich działań i decyzji ograniczających negatywne skutki dla całego systemu.
W każdym z wymienionych wyżej przypadków konieczne jest zabezpieczenie archiwizowania danych poza obszarem integracji z SI oraz ciągły nadzór, a optymalne zatwierdzanie decyzji o istotnych zmianach parametrów pracy systemu przez operatora. SI na tym etapie normalizacji, a w zasadzie jej braku, powinna stanowić tylko opcję lub wsparcie jako asystent lub doradca, ale decyzje powinien podejmować operator.
Innym przykładem zastosowania tego typu algorytmu genetycznego w sektorze energetycznym, ale na poziomie odbiorów jest współpraca regulatora węzła z zapotrzebowaniem budynku oraz aktualnymi i prognozowanymi parametrami nośnika ciepła. Maszynowe uczenie się polega w tym przypadku na dostosowaniu parametrów pracy na podstawie analizy przyrastającej bazy danych w celu prognozowania i minimalizacji błędów tych predykacji oraz doskonaleniu statystycznej istotności dopasowania modelu. W tym przypadku ryzyko wynikające wewnętrznej lub zewnętrznej dysfunkcji SI jest niewielkie, łatwo wykrywalne – jako anomalia w ramach ciągłego monitoringu pracy odbiorów lub zgłoszenia odbiorców. Efekty są lokalne i łatwe do usunięcia, aczkolwiek też wątpliwe co do dochodzenia z tytułu odpowiedzialności za szkody.
Konieczność transformacji ciepłownictwa wymaga podejmowania decyzji inwestycyjnych, w których może pomóc metoda rankingowa. Transformacja powoduje ciągłą zmienność baz danych i aktualizacji ich konfiguracji oraz wzajemnych zależności w systemach ciepłowniczych, czego skutki może niwelować maszynowe uczenie się. Dane generowane i gromadzone w systemach ciepłowniczych dzielimy ze względu na ich zmienność w czasie na dwie kategorie: dane statyczne oraz dane dynamiczne. Macierze panelowych danych statycznych służą do symulacji procesów na podstawie uproszczeń działania procesu. Uproszczenie to polega na wykorzystaniu regresji obserwacji parametrów procesu do średniej i wykorzystanie ich w formie założeń modelu statycznego. Tego typu modele wykorzystywane są na przykład do analizy rozbudowy sieci, efektu przyłączenia nowych źródeł lub odbiorów. Inną formą ich wykorzystania jest analiza ekonomiczna rentowności projektów inwestycyjnych, czy analiza wielokryterialna. Dane dynamiczne, czyli tzw. wirtualny bliźniak, służą modelom dynamicznym umożliwiającym poprzez uczenie maszynowe na kontrolę i optymalizację pracy systemów w czasie rzeczywistym. Są to modele prognozowania szeregów czasowych i danych panelowych. Wykorzystują modele regresji oparte na korelacjach zmiennych. Problem z bazą danych pracy sieci jest jej zmienność w danym systemie wywołana zmianą konfiguracji źródeł wytwarzania w przypadku źródeł rozproszonych. W mniejszym stopniu rozbudową sieci i przyłączaniem nowych odbiorów. Systemy ciepłowniczą korzystają tu z rozwiązań SI w całym spektrum, tj. uczenia maszynowego, rozumowania maszynowego oraz robotyki. W takim zastosowaniu powierzenie decyzyjności autonomicznym systemom rodziłoby ryzyko dużej skali strat bez przemyślenia zabezpieczeń, o których wyżej.
Przyszłość zastosowania SI w systemach elektroenergetycznych to ewolucja włączania kolejnych użytkowników sieci, wymiany danych oraz form interakcji. Dane z sieci i liczników budynków mogą być wykorzystywane w sposób zgodny z GDPR i bezpieczne do optymalizacji sieci ciepłowniczej z natychmiastowym i pozytywnym efektem technicznym i finansowym dla przedsiębiorstw i odbiorców. Porównując temperatury i przepływy wody można ocenić, które budynki wykorzystują ciepło efektywnie, a które nie. Można już obecnie zidentyfikować co w danym budynku zawodzi, co umożliwia optymalizację instalacji budynkowych.[4] W Elektrociepłowni Ciechanów pierwszym krokiem w takiej interakcji jest uruchomienie e-bok dla odbiorców, który prezentuje graficznie historię parametrów budynku, tj.: moc, zużycie ciepła, nośnika, czy temperatury oraz wartość kosztów. To kolejny krok do świadomego korzystania z ciepła z wykorzystaniem robotyki. Kolejnym krokiem po stronie odbiorców jest wdrażanie rozwiązań inteligentnego budynku, które mogą komunikować się z siecią tworząc jeszcze bardziej precyzyjną dla obu stron predykację popytu i podaży z zastosowaniem SI. Po stronie przedsiębiorstwa nie rodzi to istotnych ryzyk, gdyż nadal dostaje zagregowane dane i jedyną koniecznością jest zabezpieczanie dostępu do własnego systemu na poziomie połączenia systemu w ramach komunikacji. Inteligentny budynek to co innego. Zbiera dane z poszczególnych lokali, które mogą mieć charakter danych wrażliwych i mieć wpływ na czyjeś bezpieczeństwo. Jednak to sfera do działań właściciela lub zarządcy. Jeśli chodzi o ewolucję SI w zakresie zmiany form komunikacji na bardziej przyjazną i ludzką, to można to sobie wyobrazić w analogi do asystenta google. Obecnie jeszcze bazy danych, wyniki modelowania są wizualizowane na ekranach komputerów w skomplikowanych schematach lub tabelach wyników. Interakcja bezpośrednia, która kojarzy się z komunikacją jest ograniczona do niemych cyfr lub stwierdzeń na ekranie. Sztuczna Inteligencja stosowana w energetyce nie przyjmuje ludzkich cech, a kojarzy się z nadal głównie z robotyką, tj. pomiarami, oprogramowaniem monitorującym i analitycznym lub robotami mającym zastosowanie w procesach przemysłowych produkcji, czy logistyki. Jednak można sobie wyobrazić naszą interakcję z SI w przyszłości na zasadzie całodobowego doradcy, asystenta, a nawet współpracownika, z którym będziemy analizować warianty rozwiązania problemu technologicznego. Będziemy dyskutować z SI, który ze scenariuszy jest najbardziej prawdopodobny i jaka decyzja będzie optymalna. SI będzie nas nie tylko ostrzegała przed ryzykiem ewentualnej awarii i dawała wskazówki jak jej zapobiec, ale samo zorganizuje proces naprawy lub działania profilaktyczne i tylko złoży raport efektów. Jednak musimy pamiętać, że ma ona istotną słabość, związaną z faktem, że jej wnioski, sugestie, decyzje będą opierać się na analizie danych z przeszłości, które nie uwzględniają pojawiających się nowych zjawisk, urządzeń, sytuacji. Czyli nie dostrzeże ona „czarnych łabędzi”, a będzie musiała mieć czas na identyfikację i implementację zmian. Z tej słabości Sztucznej Inteligencji opartej o dane ex post trzeba zdawać sobie sprawę. Jej prognozy ex ante zweryfikują dopiero fakty. Ryzykiem jest tu błędna interpretacja SI zaimplementowanych danych, która może prowadzić do nieprawidłowej pracy systemu, wzrostu kosztów przy niedotrzymaniu parametrów jakości lub nawet poważnych awarii związanych z brakiem dostosowania ciśnienia, czy temperatury do parametrów dopuszczalnych. W tym przypadku ryzyko ogranicza każdorazowa ingerencja człowieka w decyzje i działania SI, w tym zatwierdzanie zmian oraz alarmowanie o anomaliach lub przekroczeniu zakresu tolerancji, zwłaszcza związanych z zagrożeniem zdrowia lub istotnym uszkodzeniem mienia. Kwestię tej słabości mogłaby może poprawić skutecznie wspólna, branżowa baza danych „karmiona” danymi wszystkich funkcjonujących systemów. Z agregacją podobieństw systemowych. Zwłaszcza w obszarze wytwórczym, powtarzalnym w analogicznych warunkach pracy i poddającym się tym samym analizie prawdopodobieństwa. Trzeba jednak podkreślić, że systemy ciepłownicze łączące w dany, specyficzny lokalnie, sposób źródła wytwórcze, sieci ciepłownicze, sieci energetyczne oraz odbiory nie są łatwym obszarem dla korzystania z analogii i wspólnej bazy danych na poziomie kraju. Pewne procesy prawdopodobnie poddałby się standaryzacji, jednak dynamika i zmienność charakterystyczna dla danej lokalizacji i danego układu utrudniałaby unifikację wnioskowania i mogłaby prowadzić do istotnych błędów w efektach pracy SI. Możliwe też, że Sztuczna Inteligencja byłby w stanie skorygować te błędy w procesie uczenia się maszynowego, dlatego warto byłoby rozważyć stworzenie wspólnej bazy danych na wzór systemu elektroenergetycznego dla optymalizacji pracy systemu ciepłowniczego gdziekolwiek i kiedykolwiek. W energetyce postrzeganej jako system elektroenergetyczny procesy są bardziej zunifikowane. Jednak należy zauważyć, że jest to system współistniejący, połączony poprzez elektrociepłownie z system ciepłowniczym, a praktyka zastosowania oraz oczekiwania co do roli Sztucznej Inteligencji w przyszłości są analogiczne.
Jak wspomniano wyżej, można sobie wyobrazić przyszłość tej interakcji jako rozmowa dyspozytora z jego wirtualnym odpowiednikiem, który raportuje mu parametry pracy sieci wraz z prognozą na kolejne godziny jego dyżuru oraz rekomenduje podjęcie decyzji, które zoptymalizują pracę systemu pod względem technologicznym oraz ekonomicznym obu systemów sieciowych. Zanim jednak dojdzie do takiego poziomu interakcji algorytmu z człowiekiem, który powoła do życia wirtualnego współpracownika analizującego w czasie rzeczywistym wirtualnego bliźniaka sieci aktualizując swoje DNA muszą powstać akty normalizujące odpowiedzialność i rozwiązania ograniczające ryzyko efektów „depresji” SI lub utraty nad nią kontroli. Taki skok do przodu oznacza bowiem stworzenie opcji autopilota ze wszystkimi ryzykami i wysoką skalą zagrożeń wynikających z powierzenia decyzji SI z pominięciem zatwierdzenia ich przez człowieka. Można ograniczyć się do poziomu dzisiejszego autopilota zachowania zadanych parametrów pracy bez prawa ich zmian bez zatwierdzenia przez człowieka. Jednak byłoby to ograniczeniem rozwoju tej dziedziny technologii. Wdrażanie Sztucznej Inteligencji jest tworzeniem i korzystaniem z algorytmów opartych o dwustronną inteligentną komunikację w ramach interakcji człowiek – SI, bez ograniczeń dla poprawy jakości i komfortu życia.
Strategia Komisji Europejskiej w zakresie SI i jej zastosowania w przemyśle, w tym w energetyce ma potencjał większy niż 1,5 biliona euro. Ta prognoza obejmuje również dane z systemów ciepłowniczych i ich synergii z systemem elektroenergetycznym. Obecnie są to dwa odrębne światy, które łączą się tylko w procesie bilansowania, ale w realiach w Polsce nie widzą wzajemnego potencjału uzupełnienia się z jednaj strony oraz zagrożeń utraty mocy z drugiej. Tymczasem jeśli nie wykorzystamy ogromnej ilości danych, które są dostępne już obecnie w obu systemach nie dokona się masowa transformacja zielonej energii. IEA stwierdza, że: „Zdigitalizowane systemy energetyczne w przyszłości mogą być w stanie zidentyfikować, kto potrzebuje energii i dostarczyć ją we właściwym czasie, we właściwym miejscu i po najniższych kosztach”.
Wracając do dnia obecnego jesteśmy na poziomie uczenia się maszynowego i to obejmującego system ciepłowniczy i energetyczny od strony przedsiębiorstwa bez współpracy z budynkiem. Przed nami dużo pracy, ale przejrzyjmy co mamy obecnie do dyspozycji dla okiełznania zmian systemu ciepłowniczego i energetycznego, ukierunkowane na źródła rozproszone, kogenerację, OZE, ciepło odpadowe i synergię z systemem elektroenergetycznym. W celu budowy nowej generacji smart grid uwzględniając analizę ryzyka.
Przypisy:
1. https://www.gov.pl/web/ai/czym-jest-sztuczna-inteligencja2; data dostępu: 01.11.2023.
2. Ibidem.
3. https://digital-strategy.ec.europa.eu/pl/policies/european-approach-artificial-intelligence; data dostępu: 15.10.2023.
4. https://nowoczesnecieplownictwo.pl/analiza-danych-i-jej-zastosowanie-w-cieplownictwie, data dostępu: 01.11.2023.
Autor: Dr inż. Małgorzata Niestępska, Państwowa Akademia Nauk Stosowanych im. Ignacego Mościckiego w Ciechanowie
(artykuł z wydania 5-6/2023 “Nowa Energia”, Fot: pixabay)


